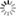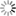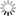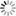Taggers and chunkers
Tagging
- 86,104 single-word lexical units, like unir (unite), inmoralidad (immorality), allí (there), etc.;
- 25,721 multi-word lexical units (MWLU), like muerte cerebral (brain death), carga de profundidad (depth charge), ácido graso no saturado (unsaturated fatty acid), etc.
Each form in the expanded dictionary is associated with a set of tags that supply information about:
- the lemma,
- the POS, and
- the inflectional properties of:
- verbs (mood, tense, person, and number), and
- nouns, adjectives, and past participles (gender and/or number).
The output of the tagger is a set of finite state automata (FSAs) -- one per sentence -- whose transitions are tagged with the wordform information supplied by the electronic dictionary (see Fig. 1). The FSAs are displayed using a graphical interface that also allows us to create or redraw FSAs and finite state transducers (FSTs).

Fig. 1. The sentence Envió la propuesta al ministro de defensa ('send.3sg the proposal to the defense minister') tagged and converted into an FSA.
Resolving ambiguities
Wordform-level ambiguities are represented in deterministic finite state automata (DFSAs) as different possible transitions between two consecutive states. Graphically, ambiguities are shown as different transitions inside a state, which is represented as a box (see Fig. 1). For instance, the second state of the DFSA of Fig. 1 shows the ambiguities of the form la, which is tagged as:
- a feminine singular determiner associated with the lemma el (the);
- a feminine singular clitic pronoun associated with the lemma lo (it, him); or
- a masculine singular noun associated with the lemma la (the musical note A).
Similarly, the third state of the DFSA of Fig. 1 shows the amguities of propuesta (proposition), which is tagged as:
- a past participle of the verb proponer (propose); and as
- a singular form of the feminine noun propuesta.
Ambiguities like the ones just mentioned can be resolved by intersecting the tagged DFSAs (see Fig. 1) with FSTs that specify local disambiguating conditions. For instance, past participles are not usually preceded by masculine or feminine clitic pronouns unless they are followed by nouns. Thus the following FST would resolve the ambiguity of the NP la propuesta (the proposal) in sentence (1).
( <DET> + <CLI:m> + <CLI:f> ) (<V:PP> + <N> ) !<N> ---> <DET> <N>
This FST can be further refined by specifying local conditions of gender and number agreement inside the NPs.
Multi-word verb recognition
Multi-word verbs are recognized by intersecting the output of the tagger with FSTs which specify their relevant lexical properties. MWLU recognition can sometimes be part of the desambiguation process. For instance, recognizing a multi-word verb when there are clitic pronouns, adverbs or other lexical material between the verbal head and the rest of a multi-word verb (MLV) (see Fig. 4) can be done by intersecting the output FSA of the tagger with a FST that specifies the position and the type of lexical material that can appear inside an MLV (see Fig. 3). MWLU recognition, and elimination of ambiguities related to lexical forms inside multi-word verbs are carried out simultaneously with 2,000 FST that specify lexically relevant properties of multi-word verbs. For example the FST in Fig. 3 chunks the multi-word verb dar por sentado (take for granted). The transducer transforms the chunked expression so that the multi-word verb is converted into a single lemma: Fig. 4 shows the FSA of sentence Max da siempre por sentado demasiadas cosas (Max takes always for granted too many things), and Fig 5 is the transduced FSA, where da siempre por sentado has been detected and converted into a single-lexical unit, i.e. a single transition in the resulting FSA. The adverb siempre (always) has been moved after the verb, which is the default position in Spanish. Note that the transduction process has also removed word ambiguity inside the chunk s. After the chunking process, these forms are no longer ambiguous, because the lexical construction that defines the FST removes all ambiguties after identifying the corresponding LU.
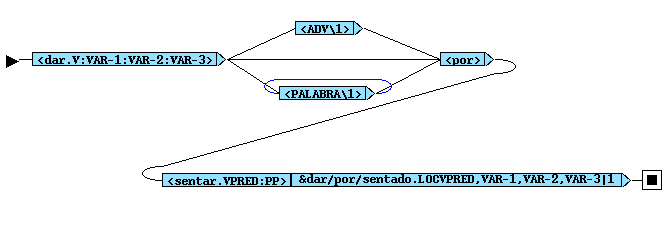
Fig. 3. Subsequential FST that detects the multi-word verb dar por sentado. The tag PALABRA (word) matches any word sequence, from 0 up to 4 words.
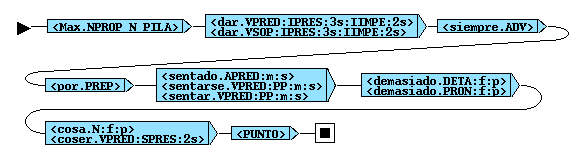

Fig. 5. Output DFSA of the sentence Max da siempre por sentado demasiadas cosas (Max takes always for granted too many things) after the intesection and transduction. The recognized multi-word verb appears in the green box.
Chunking
Chunking is carried out by using FST that specify:
- all single and multi-word verbal forms (except passive forms), like estamos estudiando (are studying), ha estado trabajando (has been working), etc.;
- noun phrases (NPs), and
- prepositional phrases (PN).
Advantages of the SFN tagging and chunking system
The advantages of the SFN tagging and chunking system over other systems that also use electronic dictionaries are threefold. First, the SFN system includes the largest Spanish electronic dictionary of MWLU available:
- 25,721 nouns, adjectives, adverbs, and predicative prepositional phrases, like en peligro (in danger), etc., which are automatically expanded in 55,000 inflected MWLU forms.
Second, the SFN system includes 3,009 FST of 2043 multi-word verbs, like dar por sentado (take for granted), etc. (cf. Fig. 5). These FST allow both:
- recognition of MWLU --even if there is lexical material like clitic pronouns, adverbs, etc., between the head and the rest of multi-word verb as shown above--, and
- simultaneous disambiguation of the constituents of the lexical forms involved in the recognized MWLUs.
Third, the lexical coverage of our electronic dictionaries of both single and MWLU LUs has been checked against the SFN Corpus, which has 436 million words. This process allowed us both to include missing entries, and to eliminate entries which appear usually in Spanish traditional dictionaries, but do not really exist in the present-day language (whether written or oral). Eliminating unexistent lexical forms adapts the size of the dictionary to the actual present-day Spanish language, thus avoiding the noise caused by unexisting forms in natural language processing.